Discussion
Pegasystems Inc.
JP
Last activity: 31 May 2021 19:34 EDT
Job Scheduler execution logs retention period
Hi,
The full list of Job Scheduler is displayed in Admin Studio, and each execution history can be referenced as below. History includes information about start time, end time, run duration, exception, node ID, and status.
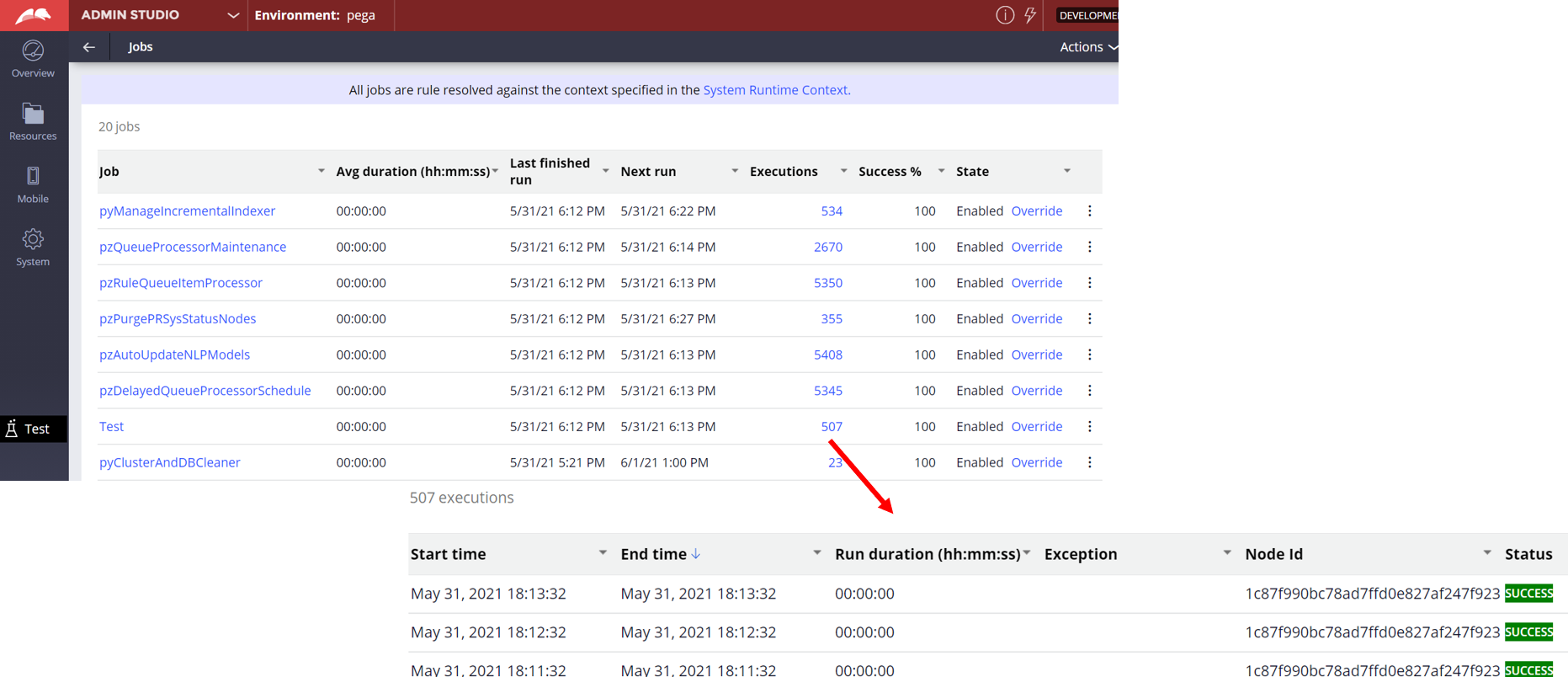
Client asks how long system can host this execution logs, and how things work. Can we customize the duration if we want? In this post, I will share my research in this regard.
- Where Job Scheduler execution logs are stored
Every time Job Scheduler is executed, the log is stored as an instance of "Log-JobScheduler" class, which is mapped to data.pr_log_jobs_scheduler table in DBMS.
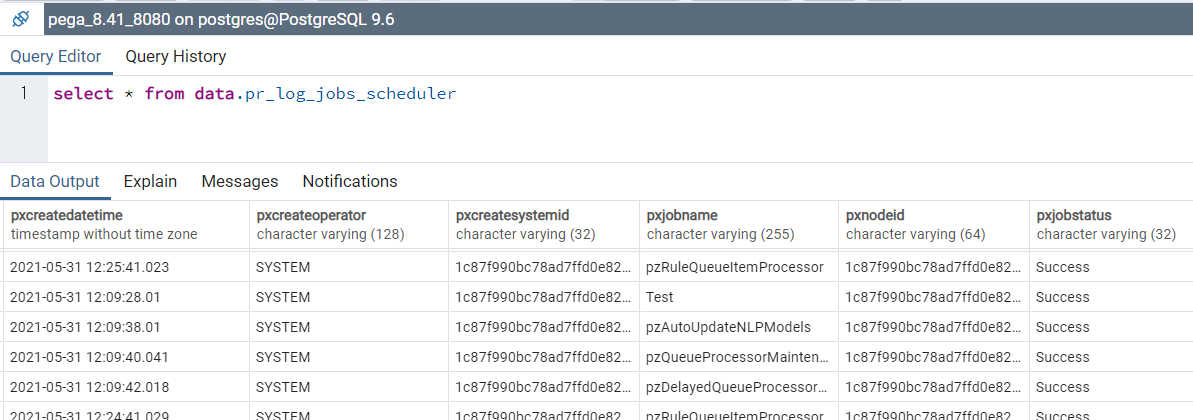
- Database table maintenance
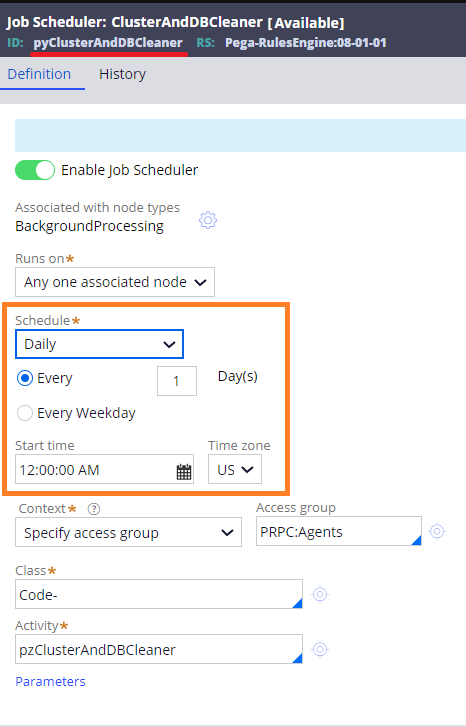
One Job Scheduler execution adds one row to this database table. Some out-of-the-box Job Scheduler are executed once per minute, and that takes up a lot of disk space. To avoid out of disk space problem, Pega prepared an out-of-the-box Job Scheduler called "pyClusterAndDBCleaner" that cleans up old rows as a part of table maintenance. This Job Scheduler runs every midnight (00:00) in US timezone.
To examine what kind of SQL statement runs, I've enabled SQL trace in PostgreSQL (*). As a result, I was able to see below DML is executed in the afternoon every day in JST. Remember, the time difference between Tokyo and New York is 13 hours during summer time, and 14 hours during winter time. So, before summer time begins, this Job Scheduler runs at 14:00 in JST as below.
delete from data.pr_log_jobs_scheduler where pxObjClass = $1 and pxCreateDateTime < $2
parameters: $1 = 'Log-JobScheduler', $2 = '2021-03-04 14:00:06.061'

During summer time, this Job Scheduler runs at 13:00 in JST as below.

If you have any performance concerns, you can override this "pyClusterAndDBCleaner" Job Scheduler and change its timezone to Asia/Tokyo, although I think this DELETE SQL shouldn't be too heavy and it is still okay to keep the default.
(*) You can enable all SQL trace by modifying postgresql.conf. Add below two lines.
- log_connections = on
- log_statement = 'all'

This change will start logging massive data on log files and this should be done temporarily for debugging purpose.
- Log retention period
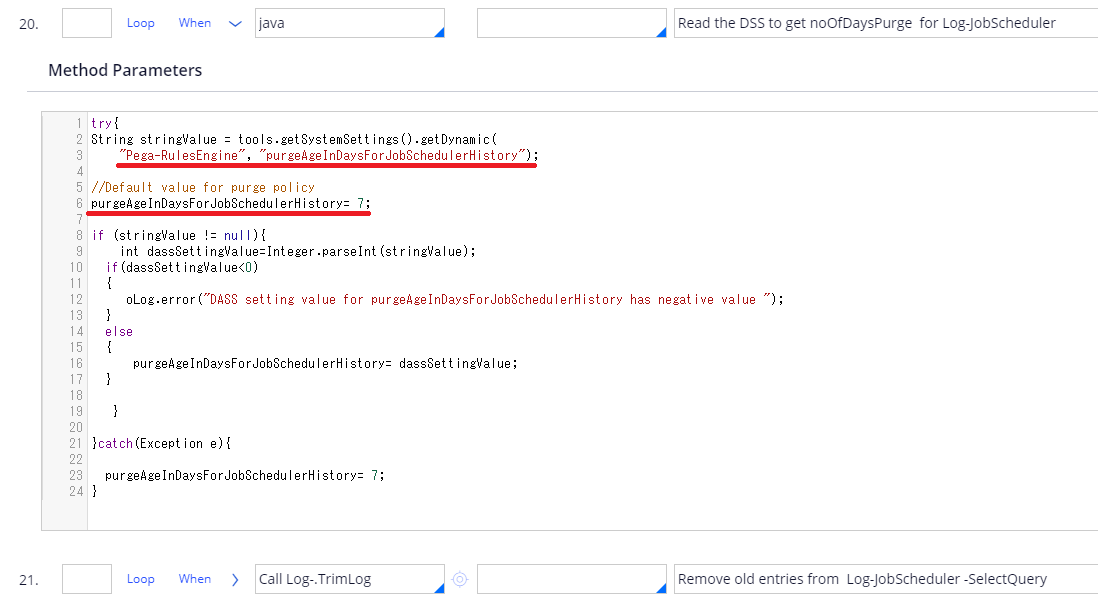
Below is the activity that gets called by pyClusterAndDBCleaner Job Scheduler. This is read, "Find Dynamic System Settings (purgeAgeInDaysForJobSchedulerHistory). If not found, apply 7 days". There is no such DSS by default, so system deletes logs that are older than 7 days.
- Customizing Log retention period
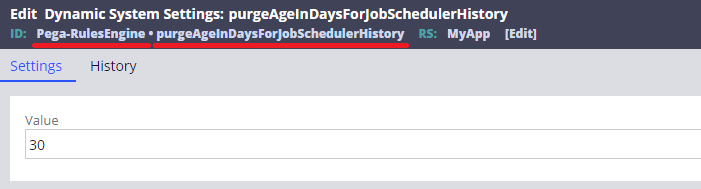
If you need to change the retention period, create a DSS called "purgeAgeInDaysForJobSchedulerHistory" in "Pega-RulesEngine" ruleset, and enter how many days you want to keep logs. If you want to keep 30 days, type 30. That said, you should be careful with extending this duration. How many rows are added depend on how you configure your custom Job Scheduler. I would recommend you ensure the customize won't lead to disk shortage issue.
Thanks,