Converting doc & docx to PDF in Pega 7.3
Hello dear community,
I have some troubles to convert Word files recieived from attachements to PDF. The context is such as, I am using Pega CRM 7.3 and I need to convert my doc/docx to sring Base64 but in such way that it is converted as PDF.
After looking a bit, I found the activity "ConvertAttachmentToPDF", which is supposed to convert doc (and not docx). I tested this activity with only .doc document first of all, but it failed. After few researches, I found this : https://community.pega.com/support/support-articles/unable-create-pdf-files-doc-files-0, explaining
that "[...] ConvertAttachmentToPDF flow action uses ActiveX integration and works only in Internet Explorer browser. Pega 7.3 and later versions do not support ActiveX controls[...]". I am using Chrome and Firefox, iIcan't be restricted to a single browser tho.
In the end, no solution is provided, only a link for some information about ActiveX, which doesn't work : https://pdn.pega.com/deprecation-microsoft-activex-controls-pega-platform/deprecation-microsoft-activex-controls-pega.
Do you have any ideas on how I can successfully make this conversion ? Thank you.
Best regards, Kévin.
***Edited by Moderator Marissa to change from Discussion to Question***
Updated: 12 Feb 2020 10:27 EST
Pegasystems Inc.
GB
Hi Kévin,
How accurate does the PDF have to be? I mean: could you extract the text and the basic structure of the WORD file (using 'doc4jx' maybe) and then create a PDF using (say) PDFBox - both libraries ship with the Pega Platform.
So the PDF would be a representation of the original WORD file - rather than being a 'screenshot' of the actual WORD file itself - depends on your use-case as to whether that would be acceptable as a 'preview' or not I guess.
Can you use a Print Driver ("Print to PDF") here? That would output the WINWORD file as a PDF - but you would (probably) need to hook out to a Windows Environment to do this.
Or - is there a Web Service which could perform the service for you?
John
Updated: 12 Feb 2020 10:27 EST
Sopra Steria Group
FR
Hi John, Thank you for your reply.
I don't know yet how accurate does the PDF have to be, I'm currently gathering informations.
Let's say I will use "doc4jx" and "PDFBox", I did not know about these libraries so, in order to use them, I should use a Java Step I guess? Do you have an "how to use" example ?
Another question, using a "Print Driver", the relationship with using a "Windows Envrionment" is because it will be saved directly on my computer or because I would have to specify a certain Path ?
And unfortunately, I don't have any WS which could do the job for me.
Thank you.
Kévin.
Updated: 12 Feb 2020 10:27 EST
Pegasystems Inc.
GB
For 'PDFBox' and 'docx4j' - yes, you would most probably need to write a combination of Activities (Java Steps as you say) and Functions to wrap the functionality. I'm afraid I don't have an examples of 'docx4j' - but you could you start by taking standalone examples (check out some of the 3rd party forums for a starting point).
You could also try using the Apache POI library (also ships with Pega Platform) here as well: in the most basic form - you could try extracting the text (losing the rich structure) and then using the OOTB activity HTMLTOPDF to generate a (basic) representation of the content. There is an example here for extracting text from a WORD file.
With regard to using a Print Driver - again, yes you would then have to figure out a way of capturing the filename which is output and saving that back to Pega. (Possibly Pega Robotics could help there).
By the way : I had a typo in my original reply - the library is called 'docx4j' (not 'doc4jx' - which sounds more like an Australian lager).
Updated: 12 Feb 2020 10:27 EST
Pegasystems Inc.
GB
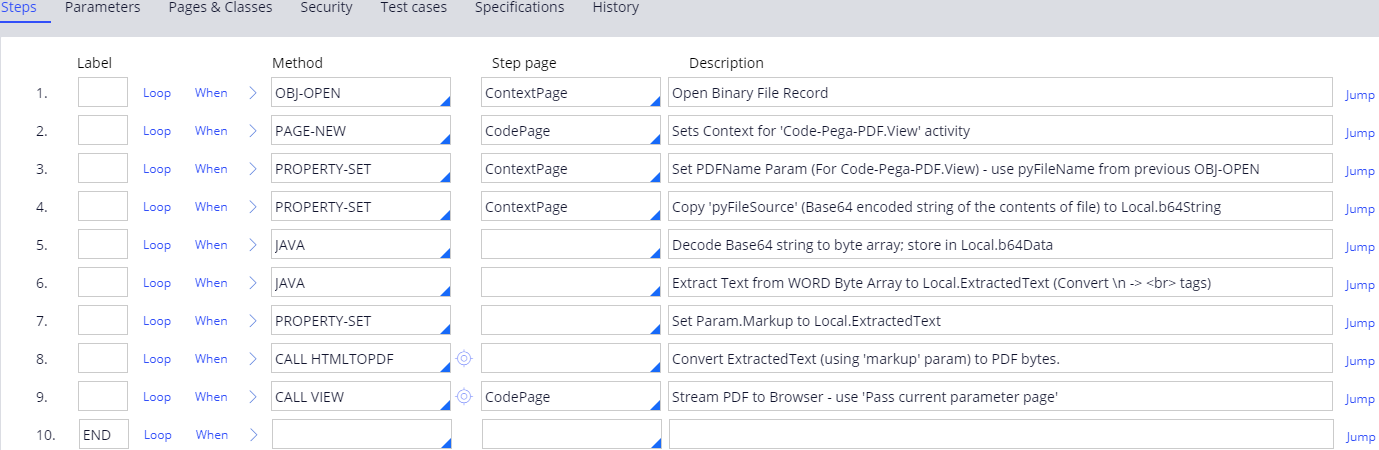
Just for reference; I was able to get a (very) basic Word (text content only - no formatting) working in PRPC8.1.x - using OOTB libraries.
Including RAP file here - it contains only a single Activity and an example WORD file (which is also attached here).
It works by opening up a Rule-File-Binary (OBJ-OPEN) of the WORD file (which I uploaded first obviously) - converting the 'pyFileSource' base64 to a binary array and then using the following code to extract the text.
STEP 5:
com.pega.pegarules.pub.util.Base64Util b64util=new com.pega.pegarules.pub.util.Base64Util();
b64Data=b64util.decodeToByteArray(b64String);
STEP 6:
// See: https://www.tutorialspoint.com/apache_poi_word/apache_poi_word_text_extraction.htm
java.io.ByteArrayInputStream bis=new java.io.ByteArrayInputStream((byte[])b64Data);
ExtractedText="";
try {
org.apache.poi.xwpf.usermodel.XWPFDocument docx=new org.apache.poi.xwpf.usermodel.XWPFDocument(bis);
org.apache.poi.xwpf.extractor.XWPFWordExtractor we=new org.apache.poi.xwpf.extractor.XWPFWordExtractor(docx);
ExtractedText=we.getText().replace("\n", "<br/>");
}
catch(Exception e) { throw new PRRuntimeException(e); }
I just used HTMLTOPDF to convert the text (after converting newlines to HTML <br/> first - to preserve line-endings).
Just for reference; I was able to get a (very) basic Word (text content only - no formatting) working in PRPC8.1.x - using OOTB libraries.
Including RAP file here - it contains only a single Activity and an example WORD file (which is also attached here).
It works by opening up a Rule-File-Binary (OBJ-OPEN) of the WORD file (which I uploaded first obviously) - converting the 'pyFileSource' base64 to a binary array and then using the following code to extract the text.
STEP 5:
com.pega.pegarules.pub.util.Base64Util b64util=new com.pega.pegarules.pub.util.Base64Util();
b64Data=b64util.decodeToByteArray(b64String);
STEP 6:
// See: https://www.tutorialspoint.com/apache_poi_word/apache_poi_word_text_extraction.htm
java.io.ByteArrayInputStream bis=new java.io.ByteArrayInputStream((byte[])b64Data);
ExtractedText="";
try {
org.apache.poi.xwpf.usermodel.XWPFDocument docx=new org.apache.poi.xwpf.usermodel.XWPFDocument(bis);
org.apache.poi.xwpf.extractor.XWPFWordExtractor we=new org.apache.poi.xwpf.extractor.XWPFWordExtractor(docx);
ExtractedText=we.getText().replace("\n", "<br/>");
}
catch(Exception e) { throw new PRRuntimeException(e); }
I just used HTMLTOPDF to convert the text (after converting newlines to HTML <br/> first - to preserve line-endings).
Resultant PDF (note formatting has been lost).

Updated: 18 Feb 2020 11:32 EST
Sopra Steria Group
FR
Hello, Thank you Jhon for your response, I was able to find a solution with this to convert doc and docx to pdf !
FYI, there are slights differences between doc and docx documents, this happens in the try of java step :
docx :
org.apache.poi.xwpf.usermodel.XWPFDocument docx=new org.apache.poi.xwpf.usermodel.XWPFDocument(bis); org.apache.poi.xwpf.extractor.XWPFWordExtractor we=new org.apache.poi.xwpf.extractor.XWPFWordExtractor(docx); ExtractedText=we.getText().replace("\n", "<br/>");
to get the text
doc :
org.apache.poi.hwpf.HWPFDocument doc=new org.apache.poi.hwpf.HWPFDocument(bis); org.apache.poi.hwpf.extractor.WordExtractor we=new org.apache.poi.hwpf.extractor.WordExtractor(doc); ExtractedText=we.getText().replace("\n", "<br/>");
to get the text.
Also, it's possible to get the the pictures byes inside the documents !
To get them, we can use the following lines :
for docx : imgByteArray = docx.getAllPictures().get(i).getData();
for doc : imgByteArray = doc.getPicturesTable().getAllPictures().get(i).getContent();
with "byte[] imgByteArray" and "i" corresponding to the image in position "i" in the list of picture provided by getAllPictures().