Question
Reply
IT
Last activity: 18 Nov 2015 7:51 EST
How to best archive multithreading and high-throughput in PEGA 7
Recently I’ve been faced with a bit of a difficult requirement.
One of our application has been running for a long time without any sort of archival and purging maintenance. So we reached a record count of about 16M in the work table and 180M in the history one.
Our customer expressed the need to carry out an archival and purging activity but without using the OOTB capability.
That’s because the customer wanted to save archived objects in a different database schema, in a partitioned table, and he basically had a plethora of additional requirements that made impossible to use said OOTB capability.
In order to reach acceptable performances I had to set up some sort of multithreading. One additional layer of complexity was that I couldn’t launch my thread in a fire and forget style (that means no Queue instruction could be used) and I had to check the output of every thread.
Basically the process to be implemented was something like that:
- start
- fire n thread
- check results when all threads are finished
- fire n-x thread
- check results when all threads are finished
The question is: how do you do that in Pega?
In my solution I wanted to keep java usage at minimum but I had to implement a few java steps in the end.
Recently I’ve been faced with a bit of a difficult requirement.
One of our application has been running for a long time without any sort of archival and purging maintenance. So we reached a record count of about 16M in the work table and 180M in the history one.
Our customer expressed the need to carry out an archival and purging activity but without using the OOTB capability.
That’s because the customer wanted to save archived objects in a different database schema, in a partitioned table, and he basically had a plethora of additional requirements that made impossible to use said OOTB capability.
In order to reach acceptable performances I had to set up some sort of multithreading. One additional layer of complexity was that I couldn’t launch my thread in a fire and forget style (that means no Queue instruction could be used) and I had to check the output of every thread.
Basically the process to be implemented was something like that:
- start
- fire n thread
- check results when all threads are finished
- fire n-x thread
- check results when all threads are finished
The question is: how do you do that in Pega?
In my solution I wanted to keep java usage at minimum but I had to implement a few java steps in the end.
What I did is to use the following method of PRRequestor class:
java.lang.Object queueBatchActivity(java.lang.String aClassName, java.lang.String aActivityName, ParameterPage aParamPage, ClipboardPage aPrimaryPage)
The beauty of this method is that you can fire a child requestor, which is as close as I can get to a multithreading logic in pega as far as my understanding goes, while keeping control of the output.
That’s because the aPrimaryPage parameter is of class type Code-Pega-Child.
If you check that class you can see that it has 2 properties:
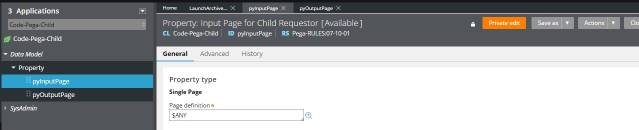
Both of type $ANY.
You can pass to your child requestor a page of a custom class with all the input data you need stored in pyInputPage property.
Then you can make it so that your multithreaded activity is going to populate pyOutputPage so your father requestor will be able to check the output.
Please note that pyOutputPage will be visible only when the child requestor will be finished. It doesn’t matter if your aActivityName activity is putting stuff in the pyOutputPage while running. You’ll be able to see that output only when the child requestor is finished.
Following is a snippet of my java step firing a child requestor:
//getting current requestor
PRRequestor requ = tools.getRequestor();
//creating parameter page
ParameterPage parametri=new ParameterPage();
parametri.putParamValue("pyTempPlaceHolder", PropertyInfo.TYPE_TEXT, "TempPlaceHolder");
parametri.putParamValue("pxObjClass", PropertyInfo.TYPE_TEXT, "");
parametri.putParamValue("pzInheritRulesetList", PropertyInfo.TYPE_TEXT, "true");
parametri.putParamValue("pzUseCurrentAccessGroupForChild", PropertyInfo.TYPE_TEXT, "true");
//renaming threadpage
ClipboardPage ThreadPage=tools.findPage("ThreadPage");
ThreadPage.rename("ThreadPage" + String.valueOf(processed_count));
java.lang.Object son=requ.queueBatchActivity("Archive-MainProcess-","SpawnArchiveThread", parametri, ThreadPage);
//create thread row
java.util.Vector row=new java.util.Vector();
//add thread
row.add(son);
//add thread page name
row.add(ThreadPage.getName());
//add index of the work being threaded
row.add(new Integer(tools.findPage("pyWorkPage").getPage("ProcessManagement").getInteger("CurrentWorkIndex")));
//add spwawned thread to vector
java.util.Vector local_vector=(java.util.Vector)threadlist;
local_vector.add(row);
There are a few things going on but nothing special really.
First, as you can see, I’m setting a few values in the parameter page (parametri) that will be used by queueBatchActivity method.
Then there is the Code-Pega-Child page, which is named ThreadPage. Before running this java step I’ve been populating the ThreadPage.pyInputPage with all the data I want to be known to my child requestor. Since this java step is running in a loop i need to change the ThreadPage name in order to avoid having it overwritten in the next iteration.
So, for example, if I’m firing 3 child requestors in my clipboard I’ll have the following pages:
ThreadPage0
ThreadPage1
ThreadPage2
The last leg of the activity is all about storing a bunch of data regarding my running child requestors in a vector which is declared as java object in my activity:

Yes, I know Vector is an obsolete class but my java foo is not top notch
Now that I have istantiated all of my child requestors the only thing left to do is to wait for them to be over.
That can be accomplished with the following method in PRRequestor class:
void waitOnAllBatchActivities(long aTimeout) throws PRTimeoutExpiredException
Once every child requestor has done his job I can loop through all of my ThreadPage checking each pyOutputPage for results.
What do you think about this approach? Have you ever found yourself in a similar situation? Are there better solutions to implement multithreading in Pega?
Message was edited by: Vidyaranjan Av
Accepted Solution
Pegasystems Inc.
US
Hi Roberto,
What application server platform are you using? Are you using ear or war deployment? You are using child/batch requestors. There are several settings you can adjust. For example, see the article for Websphere: https://pdn.pega.com/data-management/how-to-configure-a-non-blocking-ui-using-asynchronous-declare-pages. It is for different use case, but the underlying system tuning is similar. There is also a prconfig setting to control max number of child requestors for a parent (services/maxRequestorChildren default value is 10). You can tune your system as necessary.
Will table partitioning help to suffice your use case?
https://pdn.pega.com/pegarules-database/about-pegarules-table-partitioning
https://pdn.pega.com/performance/performance-guidance-for-production-applications-database
Reply
IT
Hi Aditya, thank you for your answer!
While partitioning the work and history table is surely a good option i couldn't use it in my project because i'm required to do a lot of condtional checks before archiving stuff. And sadly i can't really translate those checks in a partitioning method on oracle.
I really appreciate your feedback but with this discussion i wanted to focus more on how to obtain computation concurrency in Pega. I understand that it's not a recurring need for user oriented processes, but sometimes you may happen to have some bulk operations to carry out where you want to get things done quickly by taking full advantage of hardware horsepower
Thank you again!
Roberto
Accepted Solution
Pegasystems Inc.
US
Hi Roberto,
What application server platform are you using? Are you using ear or war deployment? You are using child/batch requestors. There are several settings you can adjust. For example, see the article for Websphere: https://pdn.pega.com/data-management/how-to-configure-a-non-blocking-ui-using-asynchronous-declare-pages. It is for different use case, but the underlying system tuning is similar. There is also a prconfig setting to control max number of child requestors for a parent (services/maxRequestorChildren default value is 10). You can tune your system as necessary.