How does Adaptive model use Predictors?
Is it good practice to define both Proposition properties along with Customer properties as Predictors? Or should only the Customer properties be used for Predictors?
While calculating Propensity, does the Adaptive model take into account other properties of the Proposition and Customer than what have been defined as Predictors? OR is it just what have been defined as Predictors - Will it check what combination of Predictors received positive responses?
If its only the defined ones, then is it fair to say just having Customer properties as Predictors will not help?
Is there any document or link available that can give more insight into how the Adaptive models work?
Pegasystems Inc.
NL
Hi Viswa,
I'm sure there are PDN articles and Academy courses that help understand Adaptive Decisioning better. Look for Decisioning, Customer Decision Hub or Decisioning and Marketing.
But let me try to briefly answer your questions here as well.
The most common practice is to have a single model per proposition and feed customer related data as predictors (usage, demographics, digital activity and so on and so forth). This is, by default, accomplished by defining the propositions in the standard issue/group/name (etc) proposition hierarchy, which is the same set of properties that are (again, by default) defining the context of the adaptive models (i.e. for every unique combination of these values, a separate model will be created). When doing this, adding proposition attributes as predictors will of course not have any effect.
It certainly is possible to use a paradigm where you partition the models by proposition attributes, or use proposition attributes as predictors, but in that case you also step away from the one-proposition-one-model paradigm. I would need to understand your particular use case in order to be able to say something sensible about that.
The propensity is only a function of the predictors. The function can (obviously) be a different for different models.
Hope this helps
Otto
Capgemini
IN
Thank you Otto for the response.
I have a follow up question. When proposition level models are created, are they based on the ID field or pxIdentifier (Proposition Identifier) from the Proposition?
The reason I ask this is after we are evaluating the propositions, we are changing the ID using a Set Property shape and then pushing it into the Adaptive Analysis data set. Also, the actual propositions get replaced (with the same ID but have not really checked if they still have the same Identifier) every quarter.
Pegasystems Inc.
NL
Hi,
Propositions are identified (by default) by pyName/pyGroup/pyIssue/pyDirection/pyChannel (+ in the case of Marketing I believe one or two extra elements). These are the same attributes that, by default, uniquely define ("partition") the adaptive models
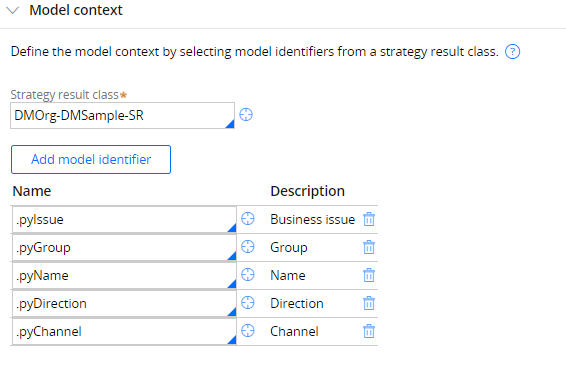
The properties are described in more detail in https://docs-previous.pega.com/default-dimension-properties-pega-72-73.
I would be very careful changing these - otherwise the responses cannot be matched against the decisions anymore...
Otto
Capgemini
IN
Hi Otto,
The screenshot that you mentioned in your message, where did you take it from?
I cannot find the confirguration at all. We are using version 7.9.1.
Thanks,
Viswa
Pegasystems Inc.
NL
7.1.9 I suppose - we're not yet at 7.9 :). The screenshot is from a 7.2.x version. In recent versions we have made the adaptive "context" configurable, in earlier versions including 7.1.9, the context is fixed.