Question
Pt. Asuransi Sinar Mas
ID
Last activity: 21 Jan 2021 18:09 EST
How to use an imported library ?
I wan to add some text into an existing PDF. So, I want to follow the step from this article https://kb.itextpdf.com/home/it7kb/examples/itext-7-jump-start-tutorial-chapter-5#iText7jump-starttutorial:Chapter5-c05e01_addannotationsandcontent
But, I have to use a new library that doesn't exist in Pega, like this
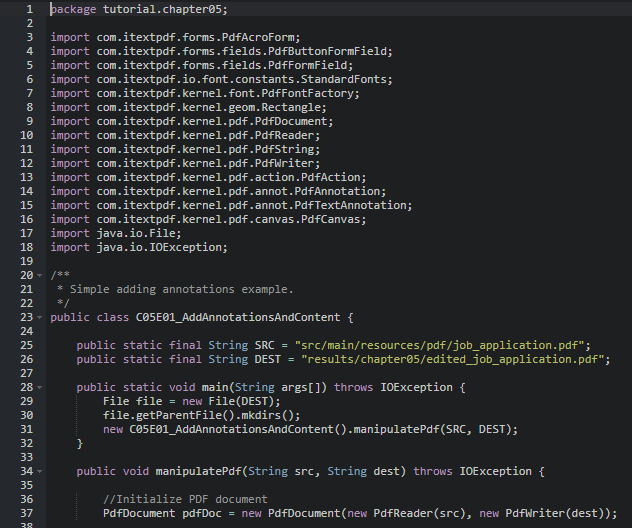
I have imported the library (.jar), and also restart Pega, but it's doesn't work when I called it on my library.
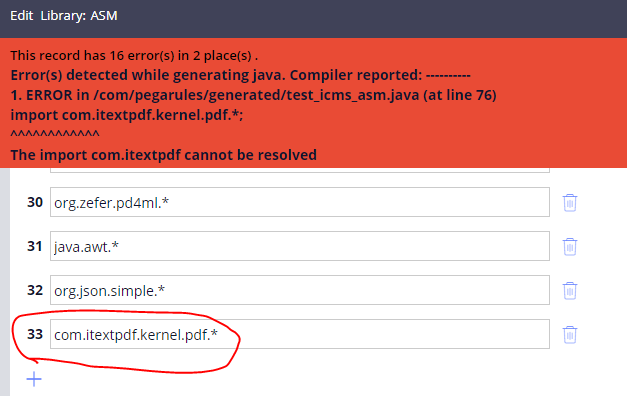
Is there any other way to use the imported library?
Thank you for helping
***Edited by Moderator Marissa to update Platform Capability tags****
Pegasystems Inc.
FR
Hello,
Can those articles be helpful maybe: https://collaborate.pega.com/question/how-do-i-import-java-library-my-application
https://collaborate.pega.com/discussion/importing-custom-java-package-library
Pegasystems Inc.
AU
What you've shown above looks fine to me.
Firstly, double-check you have followed this procedure: https://community.pega.com/knowledgebase/articles/system-administration/85/importing-custom-java-archives-and-classes
If you are in a multi-node environment you will need to restart all the nodes. Otherwise the library may be in the database but not yet be part of the 'classpath' of the node on which you are configuring your Library import statements.
Check the logs after startup to verify that the codeset you used when importing the JAR is referenced in the log messages written during startup.
Updated: 17 Jan 2021 20:36 EST
Pt. Asuransi Sinar Mas
ID
Thank you, I already can call the library.
But, how i write the below script to java in Pega?
public static final String SRC = "src/main/resources/pdf/job_application.pdf";
public static final String DEST = "results/chapter05/edited_job_application.pdf";
that script is from the article i mention before. Because i write with this code, it didn't work ("Doc.pyNote" is base64 string of my existing pdf)
try {
String src = tools.getParamValue("Doc.pyNote");
String dest = tools.getParamValue("Doc.pyNote");
//Initialize PDF document
com.itextpdf.kernel.pdf.PdfDocument pdfDoc = new com.itextpdf.kernel.pdf.PdfDocument(new com.itextpdf.kernel.pdf.PdfReader(src), new com.itextpdf.kernel.pdf.PdfWriter(dest));
com.itextpdf.kernel.pdf.canvas.PdfCanvas canvas = new com.itextpdf.kernel.pdf.canvas.PdfCanvas(pdfDoc.getFirstPage());
canvas.beginText().setFontAndSize(
com.itextpdf.kernel.font.PdfFontFactory.createFont(com.itextpdf.io.font.constants.StandardFonts.HELVETICA), 12)
.moveText(265, 597)
.showText("NO FORM")
.endText();
pdfDoc.close();
}
catch (Exception e) {
e.printStackTrace();
}
Capgemini
IN
If you are able to save the code in an activity with java method that means the library is imported properly. Now, you need to focus on the java code.
Check if you have the folder structure, as "src/main/resources/pdf/job_application.pdf" folder structure is applicable for java, by default pega server will not have this structure.
Thanks
Saikat
Pegasystems Inc.
AU
Firstly be sure that your PDF library supports what you are trying to achieve. The 'static' strings you included first above are paths to PDF documents on a file system; but you then suggest that Doc.pyNote is the (encoded) PDF content. I doubt the PdfReader(String) and PdfWriter(String) constructors can magically determine whether your String is a filename or file content. Be sure that the classes in the PDF library you are using are expecting content, not paths. That's up to you and your usage of the library, though.
From the point of view of the Pega Java API, I expect that Doc.pyNote is a clipboard reference, not a parameter. That is, your intent is to read the Base64 encoded PDF content from Doc.pyNote, transform it, then write it back to the same property on the clipboard.
Best Practice when coding Java in Pega is to implement the Java code in a Function rule, which is associated with a Library rule. Your earlier screenshots showing the Library ruleform suggest you were heading down this path, but the use of 'tools' in your latest code sample suggests you might now be trying a Java step in an Activity. Revert back to the Function/Library approach. If you are getting fully-qualified references to your library classes to compile now, perhaps the import issues you were having with the Library ruleform earlier are resolved.
Firstly be sure that your PDF library supports what you are trying to achieve. The 'static' strings you included first above are paths to PDF documents on a file system; but you then suggest that Doc.pyNote is the (encoded) PDF content. I doubt the PdfReader(String) and PdfWriter(String) constructors can magically determine whether your String is a filename or file content. Be sure that the classes in the PDF library you are using are expecting content, not paths. That's up to you and your usage of the library, though.
From the point of view of the Pega Java API, I expect that Doc.pyNote is a clipboard reference, not a parameter. That is, your intent is to read the Base64 encoded PDF content from Doc.pyNote, transform it, then write it back to the same property on the clipboard.
Best Practice when coding Java in Pega is to implement the Java code in a Function rule, which is associated with a Library rule. Your earlier screenshots showing the Library ruleform suggest you were heading down this path, but the use of 'tools' in your latest code sample suggests you might now be trying a Java step in an Activity. Revert back to the Function/Library approach. If you are getting fully-qualified references to your library classes to compile now, perhaps the import issues you were having with the Library ruleform earlier are resolved.
The advantage of the Function rule (over a Java step in an Activity) is that you can define your Function to take a parameter of type ClipboardProperty, allowing your Function to interact with that property without intricate references to 'tools' and also avoiding hardcoding a particular property on a particular page into your Java code.
Assuming your Function was named transformPdf, and had a parameter named pdfContentProperty of type ClipboardProperty, your Function would look something like this:
// 1. Get the Base64-encoded PDF content from the (Text) clipboard property
String originalContent = pdfContentProperty.getStringValue();
// 2. Initialize PdfDocument instance using 'originalContent' as input
// 3. Perform transformations on PdfDocument
// 4. Get Base64-encoded content from PdfDocument instance after transformation
String transformedContent = ...
// 5. Set the clipboard property to hold the encoded content after transformation
pdfContentProperty.setValue(transformedContent);
... then in the use case that has the Doc.pyNote property prepared with the source PDF, the Function call would be:
@transformPdf(Doc.pyNote)
This Function is reusable in other use cases where a different property on a different clipboard page needs the same transformation. Just call the function and pass the reference to the clipboard property in for its parameter.
For an out of the box example of how to use ClipboardProperty parameters in Function rules, search for PropertyHasValue and pick the result that references ClipboardProperty in its signature.
Javadoc for the classes in Pega's Public API - including the ClipboardProperty class - is available from the Engine API option on Dev Studio's Help menu:
Pt. Asuransi Sinar Mas
ID
Well, i see. So PDF library its need path for value. But, according to my need, user upload their PDF, and the system will add some text and generate the PDF again, so its may be difficult if every PDF that user uploaded must be located at server.
I found how to add some text in the other way, but its also need path as value (https://www.javamadesoeasy.com/2016/06/how-to-modify-add-text-to-existing-pdf.html)
Is there any suggestion for me to meet this need ? I already search in Pega Community, but i cant find the solution.
Pegasystems Inc.
AU
See whether there are APIs in your PDF library that work with instances of InputStream and OutputStream instead of File. If not, seek a Library that does.
Using Java's ByteArrayInputStream and ByteArrayOutputStream classes are techniques to marshall text in-memory in and out of APIs that can work with Streams of data and not have a dependency on the file system. A file system dependency adds effort for you in terms of clean-up and filename uniqueness across concurrent access, and is less Cloud-friendly than an in-memory design.
Pt. Asuransi Sinar Mas
ID
thank you for your attention.
I found another solution with this https://kb.itextpdf.com/home/it7kb/examples/itext-7-jump-start-tutorial-chapter-5#iText7jump-starttutorial:Chapter5-c05e01_addannotationsandcontent
warm regards,
Apriyanti
Pegasystems Inc.
AU
All the examples in that link use Strings pointing to filenames on the file system, so it is hard to see what solution you have.
I had a quick look at the Javadoc for iText 7 and found:
- The PdfReader class has a constructor that takes an InputStream as a parameter
- The PdfWriter class has a constrictor that takes an OutputStream as a parameter
Use these constructors as parameters to your your PdfDocument construtor, in line with the above guidance on using the ByteArrayInputStream and ByteArrayOutputStream to work with the PDF content you already have in memory.
There will be articles elsewhere on the Internet that show how to marshal instances of these streams out of a String and then back into a String.