Question
l & t infotech
IN
Last activity: 16 Oct 2018 12:03 EDT
Need to parse html content
Hi All,
We have a requirement,
we are getting caseid's information in the email and it will be html format. We need to parse the html and get the case id from it and need to search in the pega.
Could you please help us how to parse the html content to text. I know there is a option in service "inline- prefer text" but the service contain html format which we should not change.
whatever html is coming that we need to parse.
**Moderation Team has archived post**
This post has been archived for educational purposes. Contents and links will no longer be updated. If you have the same/similar question, please write a new post.
Pegasystems Inc.
GB
Do you know whether the HTML is guaranteed to be well-formed or not ? (If so: you could perhaps treat the HTML as XML and use a PARSE-XML rule here ?)
l & t infotech
IN
Thank you for your reply,
The html formatting like below. I Need Subject from each record. Please help me how to parse it? if you save as the code as html you can see the table of content which is coming and system is generating sample html code below.
Thank you for your reply,
The html formatting like below. I Need Subject from each record. Please help me how to parse it? if you save as the code as html you can see the table of content which is coming and system is generating sample html code below.
<html xmlns:v="urn:schemas-microsoft-com:vml" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:w="urn:schemas-microsoft-com:office:word" xmlns:m="http://schemas.microsoft.com/office/2004/12/omml" xmlns="http://www.w3.org/TR/REC-html40"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <meta name="Generator" content="Microsoft Word 14 (filtered medium)"> <style><!-- /* Style Definitions */ p.MsoNormal, li.MsoNormal, div.MsoNormal {margin:0in; margin-bottom:.0001pt; font-size:12.0pt; font-family:"Times New Roman","serif";} h3 {mso-style-priority:9; mso-style-link:"Heading 3 Char"; mso-margin-top-alt:auto; margin-right:0in; mso-margin-bottom-alt:auto; margin-left:0in; font-size:13.5pt; font-family:"Times New Roman","serif";} a:link, span.MsoHyperlink {mso-style-priority:99; color:blue; text-decoration:underline;} a:visited, span.MsoHyperlinkFollowed {mso-style-priority:99; color:purple; text-decoration:underline;} span.Heading3Char {mso-style-name:"Heading 3 Char"; mso-style-priority:9; mso-style-link:"Heading 3"; font-family:"Cambria","serif"; color:#4F81BD; font-weight:bold;} span.EmailStyle18 {mso-style-type:personal-reply; font-family:"Calibri","sans-serif"; color:#1F497D;} .MsoChpDefault {mso-style-type:export-only; font-size:10.0pt;} @page WordSection1 {size:8.5in 11.0in; margin:1.0in 1.0in 1.0in 1.0in;} div.WordSection1 {page:WordSection1;} --></style><!--[if gte mso 9]><xml> <o:shapedefaults v:ext="edit" spidmax="1026" /> </xml><![endif]--><!--[if gte mso 9]><xml> <o:shapelayout v:ext="edit"> <o:idmap v:ext="edit" data="1" /> </o:shapelayout></xml><![endif]--> </head> <body lang="EN-US" link="blue" vlink="purple"> <div class="WordSection1"> <h3>Records Count = 2 <o:p></o:p></h3> <table class="MsoNormalTable" border="1" cellpadding="0"> <tbody> <tr> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal" align="center" style="text-align:center"><b>EmailID <o:p></o:p></b></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal" align="center" style="text-align:center"><b>UserName <o:p></o:p></b></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal" align="center" style="text-align:center"><b>Subject <o:p></o:p></b></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal" align="center" style="text-align:center"><b>SentOn <o:p></o:p></b></p> </td> </tr> <tr> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal">1234<o:p></o:p></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal">TestUser1<o:p></o:p></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal"> Term Quote Requested: – ABCD1234<o:p></o:p></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal">2017-05-31T14:22:52.167<o:p></o:p></p> </td> </tr> <tr> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal">3215<o:p></o:p></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal">TestUser2<o:p></o:p></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal">Term Quote Requested: – ABCD5689<o:p></o:p></p> </td> <td style="padding:.75pt .75pt .75pt .75pt"> <p class="MsoNormal">2017-05-31T08:53:30.387<o:p></o:p></p> </td> </tr> </tbody> </table> <p class="MsoNormal"><o:p> </o:p></p> </div> </body> </html>
Please help me how to parse this message and subject from it. Thank you .
Coforge DPA
GB
As per your requirement you may need all 3rd <TD><P> tag values of each <TR> except first one.
You may have to create a Parse XML Rule to map these specific <TD> elements to a list property in clipboard. Then use a "Apply-ParseXML" method in activity to execute it.
If not, you can also use Java JAXP apis to parse through the XML (in your case HTML string) and read the needed values based on the specific XPATHs.
Pegasystems Inc.
GB
Unfortunately: that HTML is *not* well-formed - so you will *not* be able to use a PARSE-XML against it.
It contains two unclosed 'meta' tags in the 'head' section of the document.
You would first have to clean these up , using another method (you will need to treat this as a 'string' first, then extract out the 'clean' XML).
Additionally: this HTML (at least the version I 'scraped' from the post) is not in the default (UTF-8) encoding - it appears to be in "Windows-1252" format - you might also need to take this into account.
And lastly: I'm not sure how much control you have over the 'shape' of the incoming HTML; if the format is even slightly bit different (for instance; if text is or isn't contained with a bold "<B>" element); your mapping will fail.
But for the sake of demonstration: here's some screenshots showing how to build a PARSE-XML rule which is able to extract out portions from the (cleaned-up) XML.
I have attached the cleaned-up XML for reference.
It only maps the *first* TD element's text (which is contained with a BOLD tag); for demonstration ; but you could extend this rule to map other elements. (You could even use Repeating Structures here; but they are more complicated to build, so I went for the simpler option here).
1. Create a PRPC Text Property ; in this example "Extract":
Unfortunately: that HTML is *not* well-formed - so you will *not* be able to use a PARSE-XML against it.
It contains two unclosed 'meta' tags in the 'head' section of the document.
You would first have to clean these up , using another method (you will need to treat this as a 'string' first, then extract out the 'clean' XML).
Additionally: this HTML (at least the version I 'scraped' from the post) is not in the default (UTF-8) encoding - it appears to be in "Windows-1252" format - you might also need to take this into account.
And lastly: I'm not sure how much control you have over the 'shape' of the incoming HTML; if the format is even slightly bit different (for instance; if text is or isn't contained with a bold "<B>" element); your mapping will fail.
But for the sake of demonstration: here's some screenshots showing how to build a PARSE-XML rule which is able to extract out portions from the (cleaned-up) XML.
I have attached the cleaned-up XML for reference.
It only maps the *first* TD element's text (which is contained with a BOLD tag); for demonstration ; but you could extend this rule to map other elements. (You could even use Repeating Structures here; but they are more complicated to build, so I went for the simpler option here).
1. Create a PRPC Text Property ; in this example "Extract":
2. Create a PARSE-XML rule (From 'Integration Mapping' Category) , call it 'ExtractTextFromEmail' (but we will *change* the namespace, see below).
Change the root element to 'html' : and double-click it:
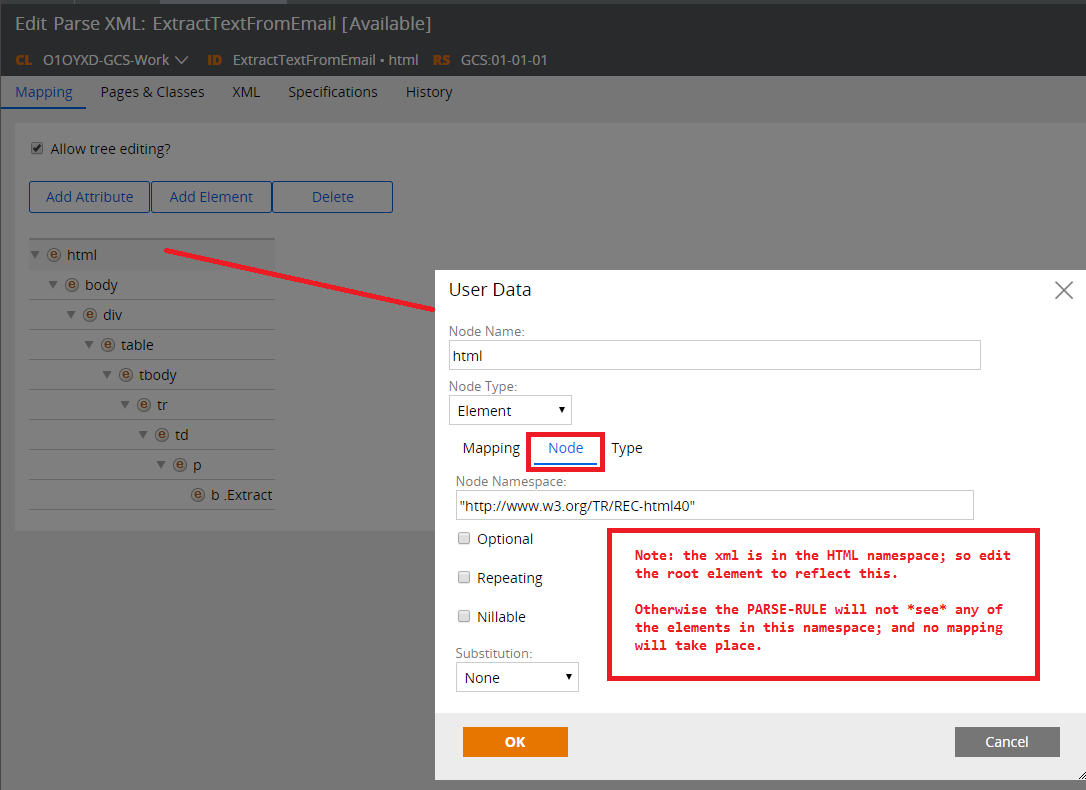 Click on the 'node' tab and change the 'Node Namespace' to "http://www.w3.org/TR/REC-html40" (because the input XML has the 'xmlns' directive set on the 'html' element).
Click on the 'node' tab and change the 'Node Namespace' to "http://www.w3.org/TR/REC-html40" (because the input XML has the 'xmlns' directive set on the 'html' element).
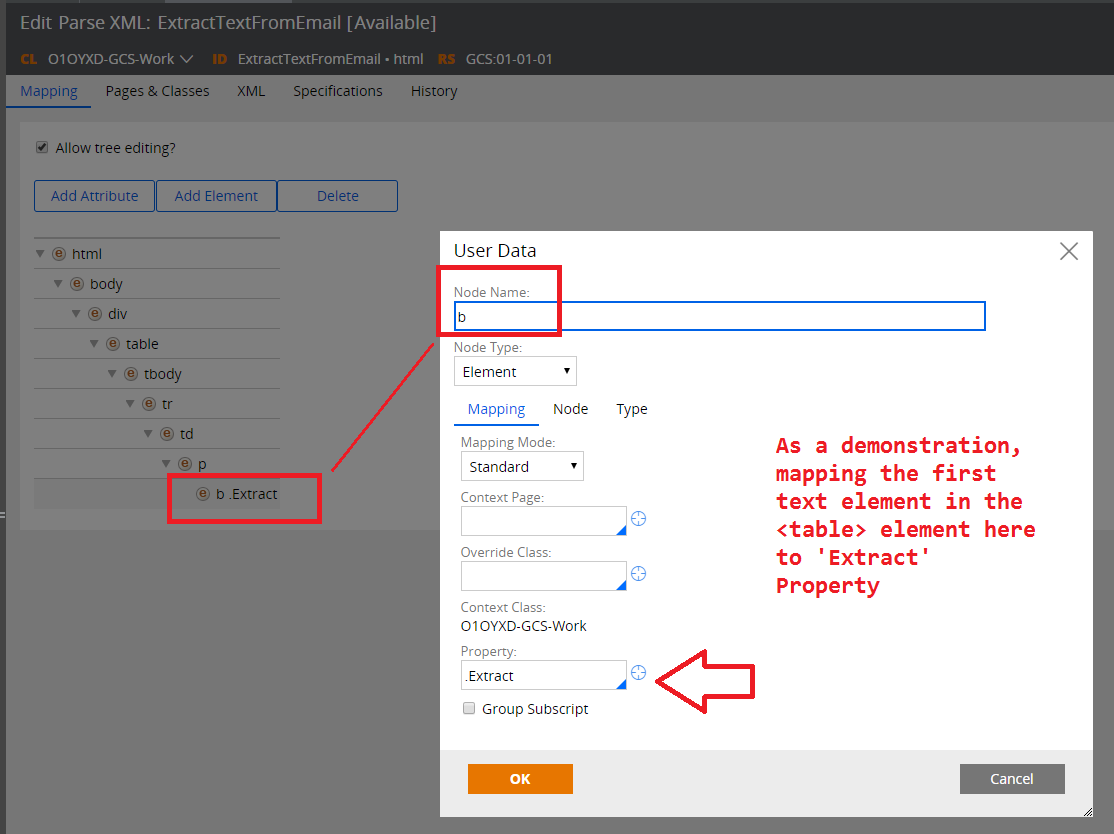
3. Follow the structure of the input XML document; use 'add element' to add in the sub-tree of html>body>div>table>tbody>tr>td>p>b
4. Map the final 'b' element to the property: (double-click the element):
 5. Test the rule: just use ACTION button > Run.
5. Test the rule: just use ACTION button > Run.
Use the option: "Text to be parsed" and copy and paste in the complete ('cleaned-up') XML and press 'execute':

Note the XML representation of the Page, correctly shows the text 'EmailID' (picked-out of the input XML) mapped to the 'ExtractProperty':
 Again, I think this approach (of trying to use PARSE-XML to process incoming HTML) isn't the ideal solution here, mainly because:
Again, I think this approach (of trying to use PARSE-XML to process incoming HTML) isn't the ideal solution here, mainly because:
1. You have to 'pre-process' the HTML to make it well-formed, and has the correct character-set directive.
2. It will break; if the incoming XML 'shape' changes.
You might want to consider building something in Java (where you can build lower-level processing - as a String etc) ,and then importing that Java as a standalone library/class into PRPC and then 'wrapping' it from PRPC.