Node type design example
Hi,
Below is my high level idea when we have four nodes - two for browser users, one for ElasticSearch, and one for Agents.
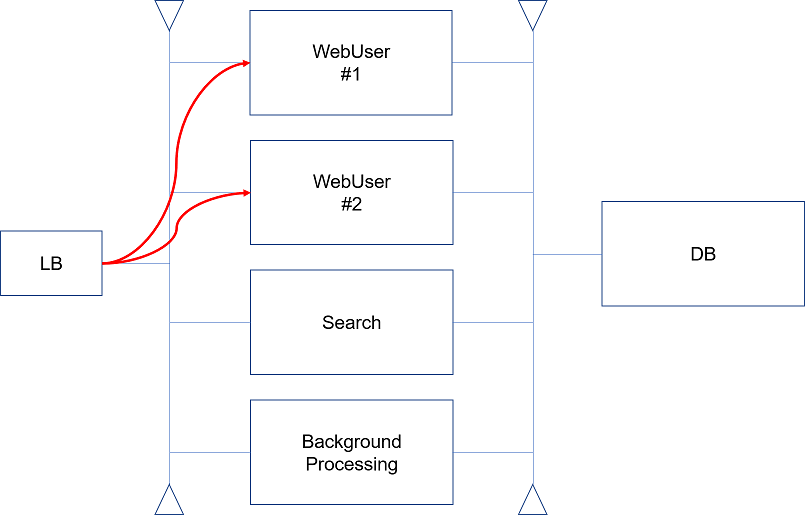
Q1. Does this diagram make sense? Any problem with this design or any suggestions?
Q2. We need LB only for WebUsers, because Search and BackgroundProcessing will not need any incoming requests from browsers, correct? But all nodes are connected on network anyways. How can I limit LB to point to only two nodes, not four nodes?
Q3. Do people really assign Search dedicated? I think it is too much for one node to do that load of work (create only index files for objects) . Why not always share it with WebUser nodes?
Thanks,
Pegasystems Inc.
US
You have got the basic design ideas right. LB has a backendpool in general, you can include only WebUser nodes. Normally search nodes does not have to be dedicated, you could include Search node type in your BackgroundProcessing node. In Pega 8.x, you do need a node of Stream type.
Updated: 28 Jun 2020 4:28 EDT
IT Solution Service
SG
Thank you for your reply. Now LB part is clear. And, it makes sense not to dedicate Search node. Please look at below modified diagram.
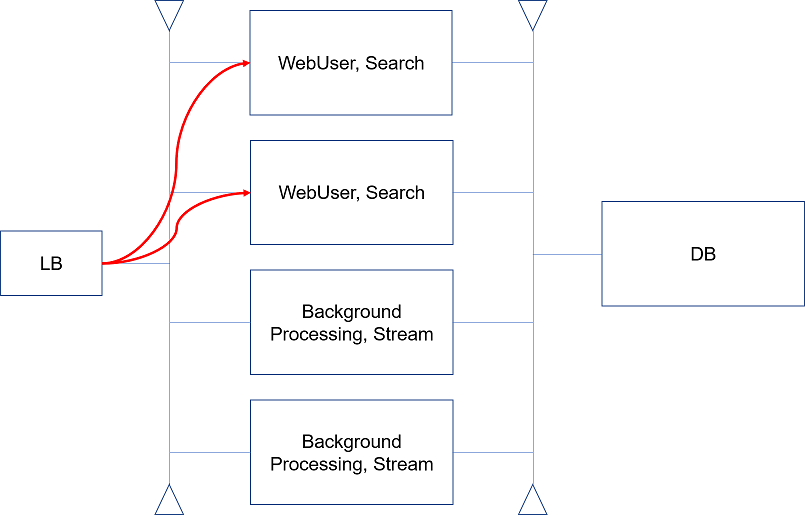
Please allow me to ask additional questions:
#1. Search node creates index files under temp directory of app server. It is not per database but per app server, that means Search has to reside in WebUser node, doesn't it? Isn't above WebUser/Search design more natural than having Search within BackgroundProcessing?
#2. I understand Stream is specially for Kafka node (Queue Processor). Agent rule is now deprecated from 8x and we are supposed to use Queue Processor. Doesn't that mean we only need Stream node and no need to have BackgroundProcessing node, does it? Is BackgroundProcessing for backward compatibility purpose?
#3. Which node type is used for "Job Scheduler" rule, which was also introduced from 8x?
Thanks,
Incessant Technologies Pvt.Ltd
AU
Hello,
For your 2nd and 3rd Questions :
Background Processing node is generally used for running Queue Processors,Job Schedulers File Listeners etc. The main purpose of this node is to run the Jobs or activities that can be triggered automatically. When a Queue Processor is configured to run on Background Processing node it will retrieve the information from Kafka and will execute on Background Node once the information is retrieved from Kafka.
Except on Web User Node,Stream node and Search node Job Schedulers can be configured on any other nodes depending on your requirement. For instance if you are having any tasks related to BIX all the Job Schedulers or Queue Processors can be configured on BIX Node if any dedicated node is there else they can be configured on BackgroundProcessing Node.
Segregating the node types helps in improving the monitoring and also it will reduce the burden on single node and to improve performance of the over all application.