Removing certain Pages in a PageList based on a condition
I am looping through Attachment Categories in a PEGA pyGetListOfAttachmentCategoriesWrapper Activity and I set .pyNote as shown below
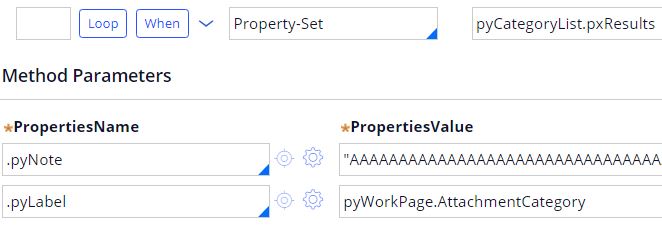
my clipboard page is pyCategoryList.pxResults is as shown below
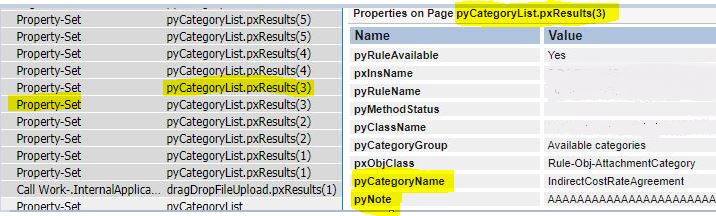
How can I remove all pyCategoryList.pxResults except for say CategoryList.pxResults(3) when a certain condition is met which I am checking as shown below?
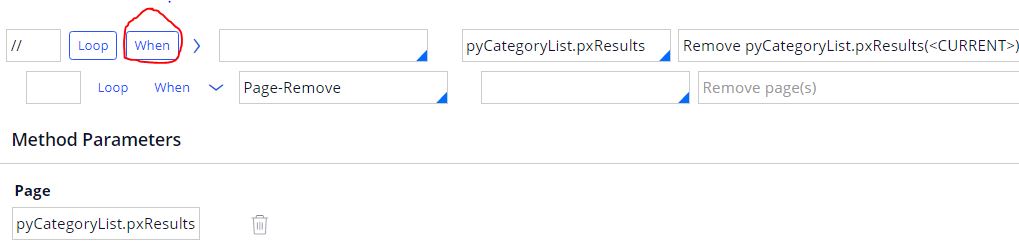
I am using Page-Remove and pyCategoryList.pxResults(<CURRENT>) as shown above.
I am getting the following Indexing error on my tracer
' java.lang.IndexOutOfBoundsException: The Reference pyCategoryList.pxResults(4) is not valid.'
Any help would be appreciated.
***Edited by Moderator Marissa to update General to Product***
Updated: 14 Jun 2021 7:38 EDT
Pegasystems Inc.
IN
We can use RemoveDeletedObjects function to removed pages from the pagelist. In the above scenario, loop through the pagelist and set pyDeletedObject to true on pages that need to be removed, and then use the function to remove the required pages.
Please find the below screenshot for a sample implementation.
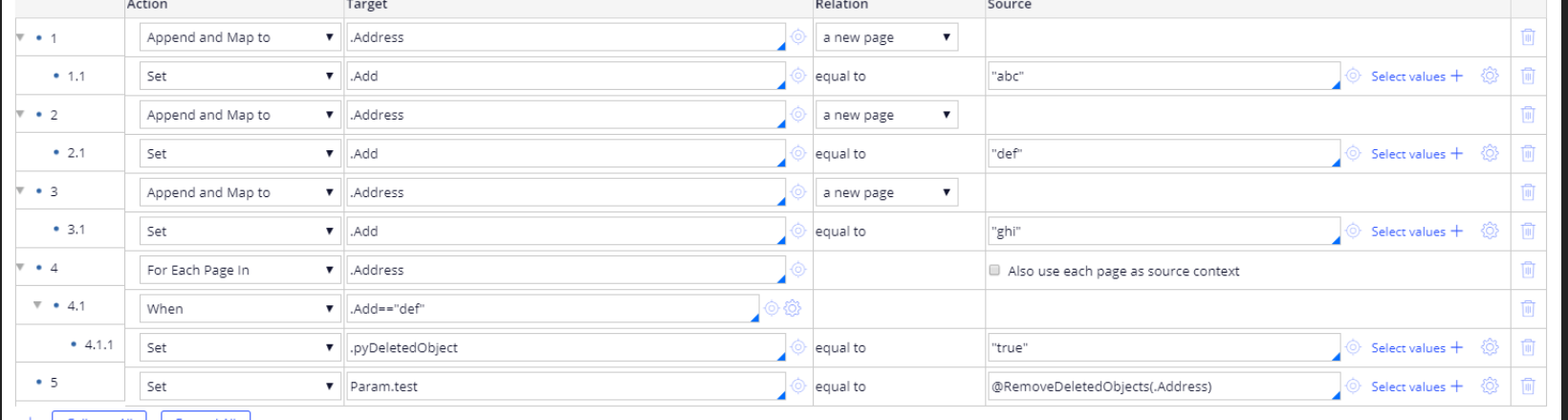
Pegasystems Inc.
US
The RemoveDeletedObjects suggestion from Pavan is a good approach.
The reason for the IndexOutOfBoundsException is that after deleting a row, the processing will continue beyond the length of the list because the list size has changed during the looping and the engine is trying to process an instance that is no longer there. To avoid this, you could loop backwards. However, I'd also recommend the RemoveDeletedObjects approach.
Accenture
US
To avoid the indexing issue, I use a temporary list that is populated by the condition that I want and then overwrite the original list with my temporary list as explained below.
I create another pagelist as 'tempCategoryList' of type 'Code-Pega-List' of the same class as my pyCategoryList, which I clear out the 'tempCategoryList' using Page-Remove.
I loop through my original Category List class pyCategoryList.pxResults and based on a certain condition, I use Page-Copy that copies that particular page (here pxResult(3)) to my temporary list (as tempCategoryList.pxResults(<APPEND>))
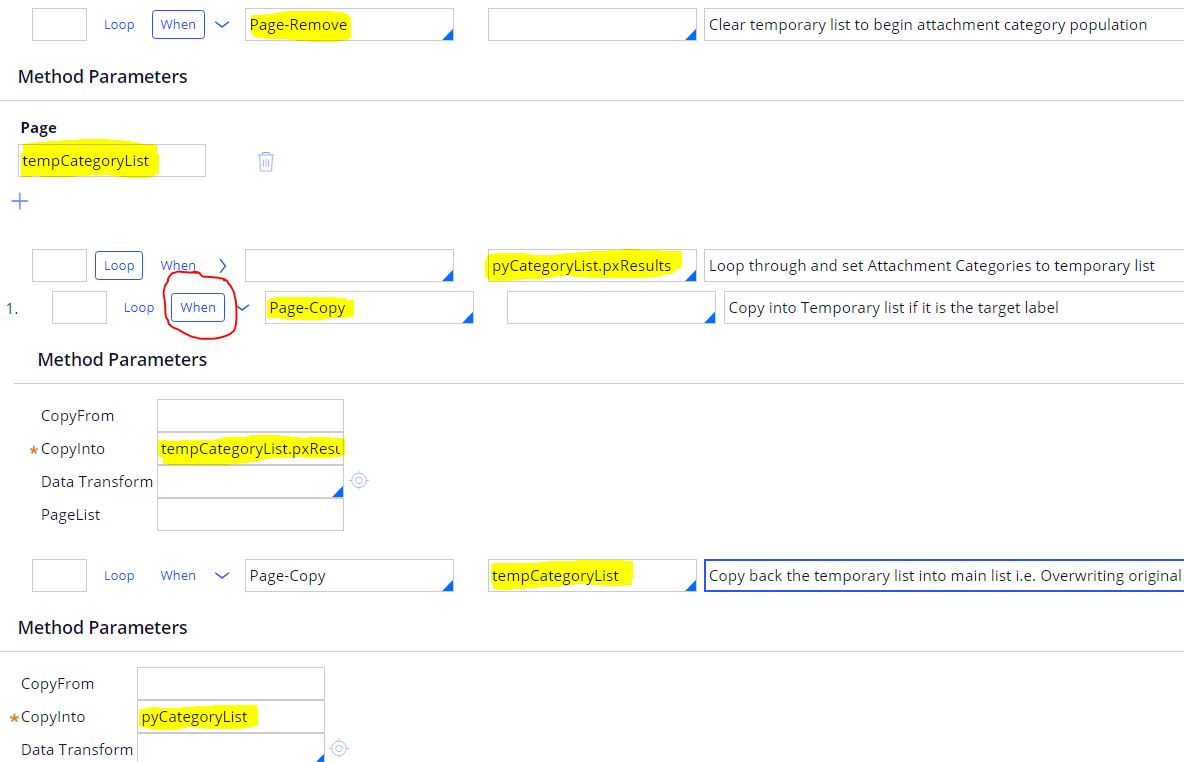
At this point my tempCategoryList has ONLY the pxResult(3) as the WHEN condition is satisfied and my pyCategoryList has all the five records.
On my last step I again Page-Copy my tempCateoryList into the original pyCategoryList, in essence I overwrite the original List which had five records and now has only the one record that I need.
Pegasystems Inc.
US
This will work, but will double the size of memory and increase CPU. With large lists the RemoveDeletedObjects is a better approach.
Accenture
US
Thanks for your input.
There is no way to escape looping through the entire List and setting RemoveDeletedObjects even for very large lists.
One iteration of the entire list is required for both scenarios i.e what I did and what you suggested using RemoveDeletedObjects.
My approach differs in that I create a new pagelist and the new pagelist I can create holds only ONE record (or a few depending on my WHEN rule).
Could you explain WHY memory size will be doubled and CPU will be increased by just creating a new pagelist and that too of a of a miniscule size, as there is no escaping iterating over a list in both scenarios (step 4 of Pavan's screen shot and looping over pyCategoryList.pxResults in my screenshot).