Discussion
Pegasystems Inc.
JP
Last activity: 27 Apr 2021 17:03 EDT
CustomerData (non-blob) vs PegaDATA (blob)
Hi,
In this post, I am going to write up my analysis regarding "CustomerData" and "PegaDATA" usage with blob topic. As you may know, Pega has added a new Database rule instance called "CustomerData" on top of existing "PegaRULES" and "PegaDATA" starting from 7.4. By default, "CustomerData" is just pointing to "PegaDATA", and initially I didn't pay much attention because it will create tables in your data schema anyways.
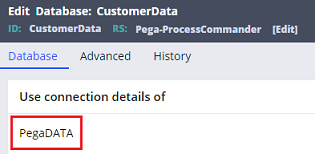
However actually internally it is quite different in how physical table gets created. If you use this new "CustomerData", blob column ("pzPVStream") is not created (some important out-of-the-box properties such as "pxCreateDateTime", "pxCreateOperator", "pxCreateSystemID", etc may still be created). Instead, if you configure source in Records tab as below, you can still create blob tables.
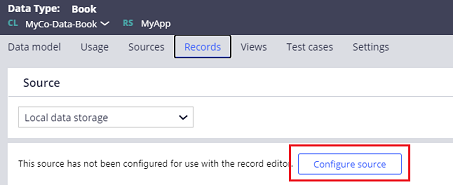

Here is how it works:
- If you select "CustomerData" (default) for Database, then Pega will create a non-blob table.
- If you select "PegaDATA" for Database, then Pega will create a blob table just like prior to 7.4 (see below screenshot).

Now, some question arises - should we always use defaulted "CustomerData", or should we choose one over the other? Please see my opinion below - I could be wrong, so please comment if you have a better idea.
In general, non-blob is better performance over blob as it won't need to use UDF to retrieve data from blob. This non-blob specification is probably part of that direction and I would say this approach is okay as most of the times you may not need blob in Data Type because you would most likely define only single value property for master data.
Having said that, I may use "PegaDATA" over "CustomerData" because of the following reasons:
- Some Data Type requires embedded pages. For example, if you want to store REST call from external system that contains nested data structure, you will need a blob to define Page List or Single Page properties. It is not possible to get page to work without blob.
- It is possible to have both blob and non-blob tables because CustomerData / PegaDATA configuration is per Data Type, but if you mix them up in both schema, it gets complex. Especially if you initially create a non-blob table and lock the rule for higher ruleset version, it will get hard to change from non-blob to blob table later. Then why not stick to one approach (blob) from the first place for simplicity.
- From performance perspectives, actually the time query takes is the same between non-blob and blob tables because custom properties are exposed anyways in blob table too. So no difference in performance.
- From migration perspectives, I see some people are confused about this "CustomerData" when importing R-A-P to different environment. Coherence to one approach (PegaDATA) may be simpler.
Please let me know if anyone has different thoughts.
Thanks,
Tata Consultancy Services
US
@KenshoTsuchihashi - This following is what I think as a particular usecaseof CustomerData schema:
if the CustomerData schema tables are used to store customer/client data that generally persisted in the blob column in the pega OOTB tables in the pega data schema; these data many a time are required for audit (financial domain related) / reporting and other similar requirements. This way we can segregate the data for specific user groups and access control at DB level. Additionally we can utilize ABAC policies to encrypt the info as well.
This may minimize running of BIX extracts (where we sometimes face challenges in presenting complicated nested page list values).
We can always implement client specific DB cipher and/or additional encryption can help the cause from a security stand point.
Thanks !